Ich wurde kürzlich angefragt, ob ich nicht ein Programm kennen würde, um aus einen Mail-Postfach alle Email-Adressen zu extrahieren. Egal, ob diese im „To“- oder „From“- oder „CC“-Feld stehen.
Leider kannte ich kein Programm, dass dafür geeignet ist, obwohl es ein solches mit Sicherheit aber gibt. Aber bei vielen Gratis-Tools oder auch Trials kann man sich nicht sicher sein, ob es Malware enthält oder ob am Ende die Email-Adressen die extrahiert wurden auch noch gleich an den Hersteller des Programms gesendet werden.
Warum diese Aufgabe also nicht einfach selber mit Python lösen? Im Internet wurde ich schnell fündig und fand die Basis für ein Skript, welches schon einmal grundsätzlich alle Adressen aus einem einzelnen IMAP-Inbox-Folder eines Postfachs (mittels imaplib) in eine Variable extrahiert: https://www.quora.com/Is-there-a-way-to-extract-email-addresses-from-all-emails-in-my-Gmail-account/answer/Jerry-Neumann
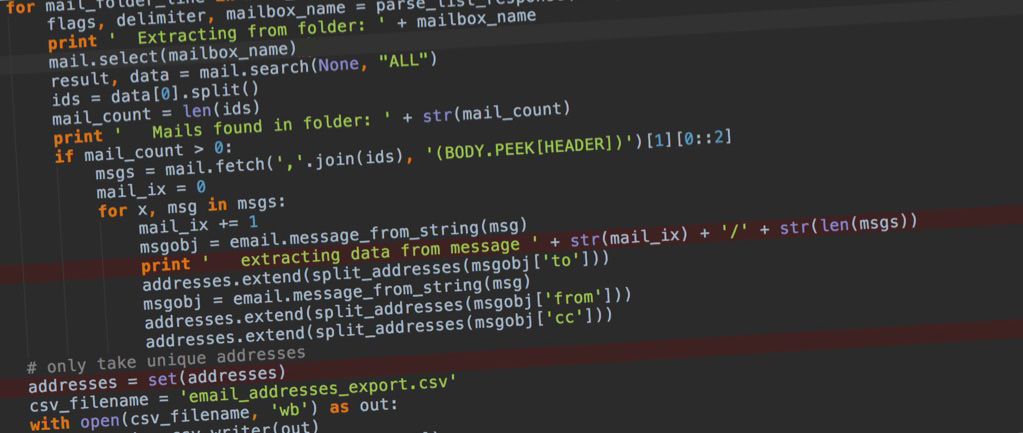
Das Skript habe ich dann etwas schöner formatiert und erweitert, dass alle Folder eines Postfachs durchlaufen und die Daten dann in eine CSV-Datei exportiert werden. Das sieht dann wie folgt aus:
import imaplib
import email
import csv
import re
list_response_pattern = re.compile(r'\((?P<flags>.*?)\) "(?P<delimiter>.*)" (?P<name>.*)')
def parse_list_response(line):
flags, delimiter, mailbox_name = list_response_pattern.match(line).groups()
mailbox_name = mailbox_name.strip('"')
return flags, delimiter, mailbox_name
def split_addresses(s):
# split an address list into list of tuples of (name,address)
if not s:
return []
out_q = True
cut = -1
res = []
for i in range(len(s)):
if s[i] == '"':
out_q = not out_q
if out_q and s[i] == ',':
res.append(email.utils.parseaddr(s[cut + 1:i]))
cut = i
res.append(email.utils.parseaddr(s[cut + 1:i + 1]))
return res
def main():
print 'Processing started...'
addresses = []
mail = imaplib.IMAP4_SSL('imap.server.com') # enter hostname eg: imap.gmail.com
mail.login('user@server.com', 'Password') # userid, password
response_code_folders, mail_folder_lines = mail.list()
for mail_folder_line in mail_folder_lines:
flags, delimiter, mailbox_name = parse_list_response(mail_folder_line)
print ' Extracting from folder: ' + mailbox_name
mail.select(mailbox_name)
result, data = mail.search(None, "ALL")
ids = data[0].split()
mail_count = len(ids)
print ' Mails found in folder: ' + str(mail_count)
if mail_count > 0:
msgs = mail.fetch(','.join(ids), '(BODY.PEEK[HEADER])')[1][0::2]
mail_ix = 0
for x, msg in msgs:
mail_ix += 1
msgobj = email.message_from_string(msg)
print ' extracting data from message ' + str(mail_ix) + '/' + str(len(msgs))
addresses.extend(split_addresses(msgobj['to']))
msgobj = email.message_from_string(msg)
addresses.extend(split_addresses(msgobj['from']))
addresses.extend(split_addresses(msgobj['cc']))
# only take unique addresses
addresses = set(addresses)
csv_filename = 'email_addresses_export.csv'
with open(csv_filename, 'wb') as out:
csv_out = csv.writer(out)
csv_out.writerow(['Name', 'Address'])
for row in addresses:
csv_out.writerow(row)
print ' CSV with addresses written to: ' + csv_filename
print 'Processing finished'
main()
Wenn ihr das Skript verwenden wollt, müsst ihr Python installiert haben und euren Mailserver und die Postfach-Logindaten eintragen:
mail = imaplib.IMAP4_SSL(‚imap.server.com‚) # IMAP-Hostname
mail.login(‚user@server.com‚, ‚Password‚) # Postfach-Benutzer-ID, Passwort